Technology is the sum of techniques, skills, methods, and processes used in the production of goods or services or in the accomplishment of objectives, such as scientific investigation. Technology can be the knowledge of techniques, processes, and the like, or it can be embedded in machines to allow for operation without detailed knowledge of their workings.
This App Lets You Use Android Auto in Any CarMon, 20 Jul 2026 14:30:00 +0000 Using a third-party tool, you can use an Android tablet or phone to stand in for an Android Auto head unit.
Samsung is betting big on the Wide FoldMon, 20 Jul 2026 08:11:45 +0000 Samsung expects more people to opt for the wide Galaxy Z Fold 8 over the flagship Z Fold 8 Ultra.
Elgato Stream Deck+ review: completely unnecessary but totally compellingSat, 04 Apr 2026 14:25:35 +0000 First, you can't see why you'd ever want a Stream Deck for your Mac, then you try one, and you will never give it back. Out of all the different models, though, the Stream Deck+ is best, and here's why.
Get a Stream Deck+ and you'll never use a Mac without one again
Every Stream Deck is a Mac accessory that provides buttons to launch apps, perform entire sequences of tasks, or turn on your smart lights. You connect it through a USB-A or USB-C cable, and the difference in the models is chiefly in how many buttons you get and whether you also have dials.
Get any of them. I've just set up a button that switches audio between my Mac and my headphones. I have one that opens all the folders for the books I'm writing. Another launches every app I need for AppleInsider, and positions them on the screen where I want.
Apple adds another office to its Sunnyvale collectionMon, 20 Jul 2026 20:20:04 +0000 Apple is expanding its presence in Sunnyvale once again by leasing a 125,800-square-foot building. If history repeats itself, Apple will buy it within a year.
The property at 580 North Mary Avenue, Sunnyvale - Image Credit: Google Maps
Companies with a massive workforce are always on the lookout for more office space. In the case of Apple, it will be adding one more location to its roster in Sunnyvale.
According to sources of the Mercury News, Apple has agreed to lease a building located at 580 North Mary Avenue in Sunnyvale. The property, which weighs in at 125,800 square foot of office space, is being leased from the Bay Area real estate firm Peery Arrillaga.
A render of what the iPhone Fold could look like - Image Credit: AppleInsider
The occasional reference leaks in Apple's beta operating systems often hint to future features that are on the way. For inbound devices like the iPhone Fold, they can sometimes point to big changes in the design.
According to an examination of the just-released fourth developer beta of iOS 27, MacWorldbelieves this is a sign that an iPhone with multiple internal batteries is on the way.
Fourth iOS 27, macOS 27 developer betas arriveMon, 20 Jul 2026 19:35:59 +0000 Apple is moving on with its developer beta program, with new fourth builds of iOS 27, macOS 27, tvOS 27, watchOS 27, visionOS 27, and iPadOS 27 now undergoing testing.
An earlier iOS 27 beta screen
The fourth round is here, and participants in Apple's developer program can download the new builds to their devices right now.
The third developer builds arrived on July 6, while the second occurred on June 22 for most of the operating systems. The watchOS 27 counterparts landed later, on June 23 and June 25.
Apple's hardware that works with the 26-generation operating systems - Image Credit: Apple
Apple is currently operating multiple beta-testing tracks at the moment. While the focus is on the 27-generation, it's current 26-gen OSes are still getting updates to version 26.6.
The RC developer betas landed after the fifth, which came out on July 13. The fourth arrived on July 6, the third landed on June 29, the second were distributed on June 15, and the first round came out on May 26.
Ruth Madeley (center) as Judy Heumann in Sian Heder's "Being Heumann" - image credit: Apple TV
In 2022, Sian Heder directed and co-wrote "CODA," which earned Apple TV the first-ever Best Picture Oscar for a streaming service. Apple immediately announced that it was backing Heder to direct a dramatization of Judy Heumann's bestselling memoir, and the finished film is now heading for theaters and Apple TV.
Co-written by Heder and Rebekah Taussig, "Being Heumann" stars Ruth Madeley as Heumann. Best known for "Doctor Who" and Russell T. Davies's "Years and Years," Madeley has spina bifida and is wheelchair-bound.
Fixing ISP-provided routers, public betas, & more on Smart Home InsiderMon, 20 Jul 2026 15:55:19 +0000 On this week's episode of the Smart Home Insider podcast, we talk about the the public beta of tvOS 27, and new product launches. Plus, Plume's Alan Coleman joins us and talks about how his company helps Wi-Fi behind the scenes.
Smart Home Insider Podcast
Guest co-host this week is Alan Coleman, chief product officer of Plume. Plume works with ISPs to help improve in-home Wi-Fi performance.
Specifically, they work with many OEM router manufacturers, provide a white-label app experience, and offer care service to help diagnose networking support issues.
The firm said the campaign has reached at least 100 targets in 33 countries since May 2026, with more than half of the identified activity in Europe. Group-IB also found targets in North America, the Middle East and Africa.
ClickLock builds on ClickFix, a familiar scam that uses fake CAPTCHA or Cloudflare verification pages to convince people to paste commands into Terminal. ClickLock adds a coercive step when a victim cancels a password prompt or refuses access.
The attack begins only after the victim copies a command from a malicious page and runs it in Terminal. The script then downloads separate components designed to steal passwords, collect browser and cryptocurrency data, access the macOS Keychain and install a persistent backdoor.
How the hidden Siri AI Writing Tools appear when you selected text.
Although some users, including ones at AppleInsider, are finding that Writing Tools have vanished in macOS Golden Gate, typically they remain available whenever selected text is right-clicked. But Reddit users have found that there is a hidden alternative that automatically pops up a short list of Writing Tools when you select text.
To try it out, you have to enter two Terminal commands and macOS will caution you that it's possible the commands are malware. They are not, and they are required to uncover this hidden feature.
Game development diary: Crunch and preparing to launchMon, 20 Jul 2026 12:05:33 +0000 The Steam launch of "Character Limit" looms thanks to a final push to get the game ready. However, while it's "done" enough for people to play, there's still the problem of actually releasing it.
The full game is in Steam, awaiting launch.
It is safe to say that developing a word game like this wasn't meant to take a year. The first installment of this series was posted on July 28, 2025.
The math is easy to figure out how long it's been since I started.
How to make Apple Journal part of a mindful daily routineFri, 17 Jul 2026 12:03:32 +0000 Apple's Journal app doesn't promise to improve mental health, but its approach to reflective writing closely aligns with what decades of psychological research actually supports. Here's why that matters, and how Apple's approach differs from most wellness apps.
Journaling with mindfulness
Journal focuses on people's thoughts and experiences instead of their bodies, unlike the data-driven health tracking with Apple Watch. The app encourages users to reflect on their emotions and pay closer attention to the everyday moments that shape their lives.
Instead of evaluating users or assigning psychological scores, Apple designed Journal as a private place for writing and memory. People can use it to revisit meaningful moments and build a habit of reflection over time.
Apple's decision to prioritize writing over interpretation aligns with decades of research showing that expressive writing can produce measurable psychological benefits (Frattaroli, 2006; Reinhold et al., 2018). Journal encourages reflection without trying to explain what users think or how they should feel.
Sunday Reboot: Shrinking models and an on-device AI futureSun, 19 Jul 2026 20:12:40 +0000 In this week's Sunday Reboot, Apple's AI model-shrinking talk could have massive benefits, with a chance of also being a billion-dollar deal if it plays its cards right.
On-device AI processing will be a big thing in the coming years if Apple bets right.
Sunday Reboot is a weekly column covering some of the lighter stories within the Apple reality distortion field from the past seven days. All to get the next week underway with a good first step.
Apple probably won't add Jony Ive to OpenAI trade secret theft suitSun, 19 Jul 2026 18:30:44 +0000 Four years ago, Jony Ive stopped working for Apple, and started working with OpenAI, yet he isn't named in the intellectual property theft suit. The reasons for that are myriad, ranging from the personal to practical.
Jony Ive & OpenAI's Sam Altman | Image Credit: OpenAI
On July 10, Apple launched what looks to become a major lawsuit against OpenAI, accusing ex-Apple employees of stealing intellectual property. However, despite former Apple design chief's links to OpenAI, he isn't in the crosshairs of Apple's lawyers.
In Sunday's "Power On" newsletter for Bloomberg, Mark Gurman writes about the lawsuit and the oddity. He believes there are two big reasons for Apple not to implicate Ive in the lawsuit at all.
Genius Bar AI tools spark concerns over employee monitoring & evaluationSun, 19 Jul 2026 14:32:54 +0000 Apple is testing a new Genius Bar tool called Live Notes that transcribes and summarizes conversations with a customer, but employees are worried about how the tool might be used against them.
Genius Bar employees may gain a new AI assistant
Artificial intelligence has become a buzzword throughout the tech industry from both the consumer and employee perspective. Employees of any kind at many companies have had to contend with mandatory AI tool use forced on them by the employer.
So far, reports haven't indicated Apple taking such a hardline route to AI tool use. However, the "Power On" newsletter from Bloombergshares that Apple is testing a new tool called Live Notes for use in the Genius Bar.
Mac Pro could have been vastly more powerful than the Mac StudioSun, 19 Jul 2026 14:31:58 +0000 Apple has dropped the Mac Pro entirely, but for a time it was planning to keep it at the top of the range, giving it twice the processing power of the company's Ultra chips — and maybe even one last Intel model.
The much-missed Mac Pro
The once beloved Mac Pro went out with a whimper in March 2026 as Apple discontinued it. But according to Bloomberg, there had originally been big plans for its future.
What eventually caused the end of the Mac Pro was how powerful the much more cost-effective Mac Studio was. From early on in the development of Apple Silicon, though, the plan was reportedly that the Mac Studio could get Apple's Ultra processors, but the Mac Pro would get more.
B&H launches steep MacBook Pro discounts at up to $400 offSun, 19 Jul 2026 07:26:26 +0000 B&H has launched new markdowns on numerous 14-inch and 16-inch MacBook Pro laptops this week, with savings of up to $400 off M5, M5 Pro, and M5 Max models.
The latest sale at B&H includes numerous CTO MacBook Pro models that are up to $400 off. Some of the configurations have additional RAM, extra storage, a nano-texture display, or all three.
You can jump straight to the sale, but we've also rounded up top picks below. And if you don't see your desired model, it's also worth checking out our MacBook Pro Price Guide, which is broken down by screen size and Apple Silicon chip, to find deals on dozens of configurations.
Over the course of a few days, Apple has been increasing the prices of its various online services. Not to be left behind, iCloud+ has now upped its prices to join the rest of the roster.
The change, revealed by Apple's iCloud+ pricing support page, doesn't outright say what countries are affected by the pricing. However, comparisons with previous pricing, including via the Wayback Machine, shows it affects eight countries in total.
Apple shares closed at $333.74, leaving the company with a market capitalization of approximately $4.88 CAP trillion. Nvidia ended down about 3.5% on the day, with a value of about $4.86 trillion.
The distinction is largely symbolic, and a lead this narrow could disappear during the next trading session, if not in after-hours trading over the weekend. Still, Apple's return to the top caps a striking reversal from the tariff, China, and artificial intelligence concerns that weighed on its shares the last time it held the position.
Is Apple One worth it in summer 2026 after the latest price increases?Fri, 17 Jul 2026 18:58:05 +0000 Following price increases for Apple Music and two Apple One tiers, Apple One still offers substantial savings for people who regularly use its included services, but the value depends on what they would otherwise buy separately.
Apple One
The Apple One bundle arrived in 2020 and has become a common option for Apple device owners who subscribe to several of the company's services. It offers three tiers aimed at individuals, families, and people who want nearly everything included.
However, favorite services can come bundled with subscriptions that receive little or no use. Apple TV viewers might not need Apple Fitness+, while Apple Music subscribers may have no interest in Apple Arcade.
Apple Music prices increased in the United States on July 17, with Individual rising by $1 to $11.99 per month, Student increasing by $1 to $6.99, and Family climbing by $3 to $19.99. Apple One Individual remained at $19.95, while Family increased by $2 to $27.95 and Premier rose by $2 to $39.95.
The Apple Music Individual plan now costs $11.99 per month, up from $10.99. The Family plan rose from $16.99 to $19.99 per month and continues to support as many as six people through Family Sharing.
Verified college students will pay $6.99 per month, up from $5.99. The Student plan includes the full Apple Music service and access to Apple TV at no additional cost.
The increases add $12 per year to the Individual and Student plans. A Family subscription will cost $36 more annually, bringing the total to $239.88 per year.
Apple's long-running DOJ antitrust case may not make it to trialFri, 17 Jul 2026 17:42:30 +0000 Apple and the US Justice Department are reportedly in early discussions over the potential for an early settlement of a 2024 iPhone antitrust suit brought about by the Biden administration.
Apple hasn't taken the antitrust case lying down. Image source: Apple
While discussions are reportedly underway, it's unclear whether an agreement will be reached. However, the Trump administration has been working to settle lawsuits brought by the previous administration for some time. It's clear there is a willingness to do a deal from their side.
Apple is also keen. Bloombergreports that Apple has already made multiple offers to the Justice Department in 2026 alone. The company previously lost a bid to dismiss the antitrust lawsuit in 2025.
Google is making no progress on switching iPhone users to AndroidFri, 17 Jul 2026 17:08:04 +0000 Existing iPhone owners continue to account for nearly nine in 10 surveyed U.S. purchases, showing how Apple's enormous customer base isn't dwindling under pressure from Google and other Android smartphone manufacturers.
iPhone 17
Consumer Intelligence Research Partners estimates that 87% of U.S. iPhone buyers in the March 2026 quarter came from another iPhone. The share reached its highest level in the three years covered by the report, up from 84% in 2025 and 85% in 2024.
Another 12% switched from an Android smartphone, down from 14% in 2025 and slightly below the 13% measured in 2024. The remaining 1% came from a basic phone, bought a first smartphone, or fell into another category.
The numbers point to a smartphone market in which most buyers settled on a platform years ago. Apple can still attract Android owners, but the larger opportunity comes from convincing hundreds of millions of existing customers to replace an older iPhone with a newer model.
Apple ordered to remove 8 'nudify' AI apps from the iPhone's App StoreSat, 18 Jul 2026 14:03:56 +0000 Apple has been accused of "aiding and abetting" the use of "nudify" AI apps on the iPhone, with San Francisco City Attorney David Chiu demanding they be removed from the App Store in a new cease-and-desist letter sent to the company.
AI nudity apps are a problem for the App Store
A Wiredreport notes that both Apple and Google have been told to prevent the sale of AI apps that can be used to create deepfake images. They must also "sever" business relationships with all of the developers responsible for the apps.
So-called "nudify" apps have been around for some time. They allow users to create non-consensual intimate images of others, often minors, without the knowledge of the subject.
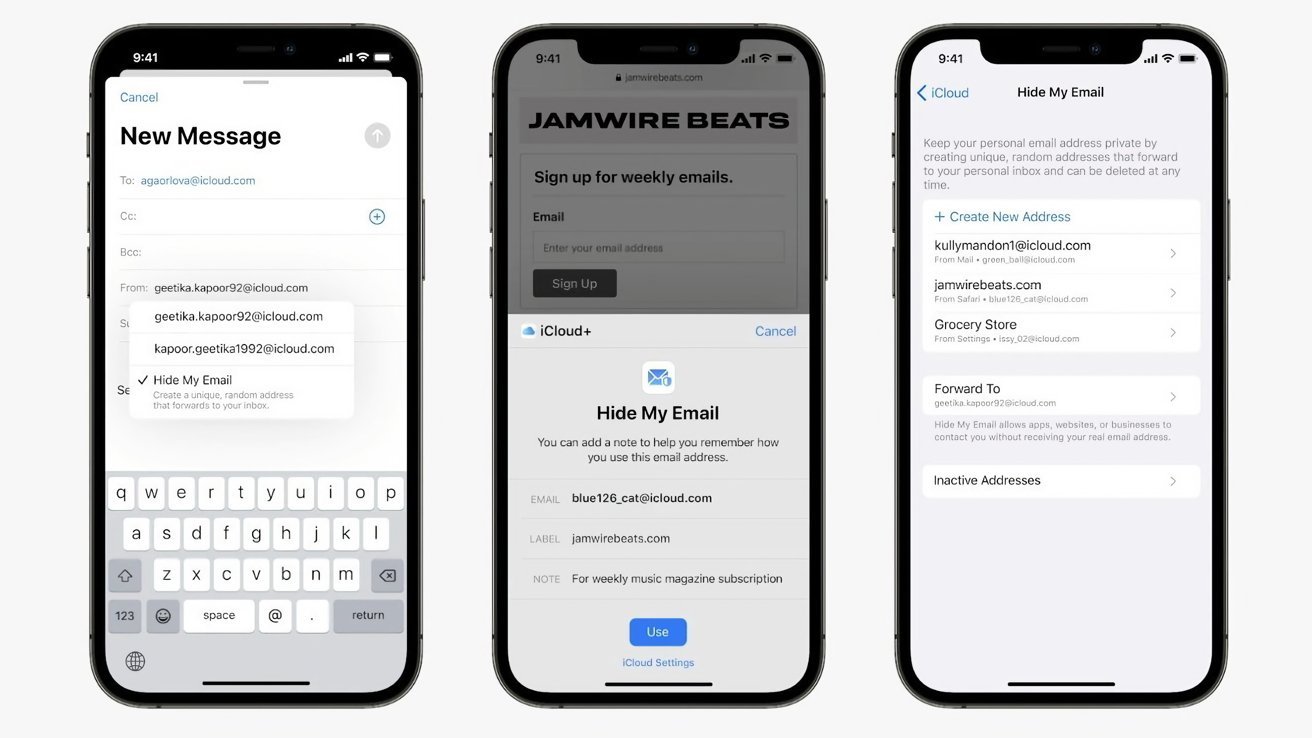
Hide My Email is supposed to do just that, but it doesn't always
The Hide My Email feature allows iPhone, Mac, and iPad owners to sign up for websites and services using an anonymous email address. All emails sent to that address are then invisibly forwarded to the user's real email address, preserving their privacy.
However, it has been reported that the feature can be bypassed, allowing someone to see a user's real address. Apple is yet to fix the issue, despite having known about it for more than a year.
Apple sues OpenAI, public betas, & super apps on the AppleInsider PodcastFri, 17 Jul 2026 13:17:43 +0000 The already tense relationship between Apple and OpenAI reaches a breaking point as trade secret accusations emerge, plus your hosts discuss EU regulations, the future of gaming, and public betas on the AppleInsider Podcast.
Apple is set to be in a lawsuit with OpenAI for some time
Apple restarted its AI efforts with new Apple Foundation Models built with Google's Gemini Frontier models at the foundation. While Google's involvement seemed obvious in the long run, the move away from OpenAI's ChatGPT may have been a long time coming.
Not only is OpenAI building hardware products meant to directly compete with Apple's, but the company has poached over 400 employees in recent years. Apple finally showed its hand with a trade secrets lawsuit that could upend OpenAI's hardware ambitions and hopes for sustainable post-AI revenue.
Apple filed a lawsuit in early July, 2026, arguing that OpenAI received trade secrets from its former employees. Former executives Tang Tan and Chang Liu were also named in the lawsuit.
Now, The Financial Timesreports that Apple has sent letters to approximately 40 former employees. The legal communications require the preservation of all relevant documentation, ensuring that it can be called upon when required.
How to add an email account to Apple Mail on Mac or iOSThu, 22 Aug 2024 03:00:05 +0000 For many, the best email app is the one that came on your iPhone, Apple's own Mail app. To get the most use out of the Mail app, you can set it up to have all of your email accounts and addresses in one place in it.
To keep all of your emails in one place, you'll have to make some additions
Whether it be on your Mac or your iPhone, the process of adding an email account to Apple Mail is quick and painless. And, most importantly, it will make sifting through your emails that much simpler.
That's because once you have added two or more email accounts to the Mail app, you have a choice of how to read them. You can go separately into each one or click on the overall inbox to see all messages from all accounts, right there in one place.
Enterprise AI is facing an ROI paradox. While throwing more compute at the strongest foundation model works well in product experiments, the costs become unbearable when the product is deployed in production.
A new paper from researchers at Writer provides a solution that is accessible to engineering teams. The study takes a systematic look at optimizing the different components of the orchestration layer that wraps around the foundation model, aka the AI harness.
By optimizing the harness, the researchers show dramatic reductions in tokens per task, a drop in cost-per-successful-task by up to 61%, and quality that holds steady, all without changing the underlying foundation model.
Because the harness is fully under the developer's control and requires no model fine-tuning, engineering teams can apply these findings to build highly cost-efficient AI applications.
The ROI crisis of tokenmaxxing
The current state of AI engineering is plagued by "tokenmaxxing," an industry trend where developers rely on massive context windows and brute-force token consumption as a substitute for good system design.
Rather than engineering elegant workflows, developers have imported a reflex from traditional software development: generate, run, fail, stuff the error and more context back into the window, and retry.
"Teams tokenmaxx because it's the cheapest fix in the moment, and because it's literally how most engineers work today," Waseem AlShikh, CTO and co-founder of Writer, told VentureBeat. Because this approach succeeds often enough on coding tasks, it has become the default reflex for every other agentic workload. The danger is that per-token price drops mask the underlying inefficiency.
"Your invoice is tokens-per-task times price-per-token, and most teams only watch the second number," AlShikh said. "In agentic workloads, tokens-per-task compounds — every loop iteration re-transmits the growing context — and it compounds faster than prices fall. The price cut becomes an anesthetic. It masks the fact that the loop itself is bleeding."
Tokenmaxxing leads to several enterprise failure modes. Teams route simple tasks to premium frontier models by default. They use the LLM as a lazy search index, stuffing the context window with raw documents instead of retrieving exact answers. Most destructively, they build unconstrained agentic loops that spiral out of control when the model encounters an error. Because output tokens cost significantly more than input tokens across all major model providers, inefficient task execution acts as a silent budget killer.
The industry has introduced several efficiency techniques to curb these costs, but they largely fall short because they treat the model in isolation:
Prompt compression condenses input text to save space, but ignores how the system sequences those inputs across complex workflows.
Budgeted reasoning caps the computational steps a model can take, which often degrades output quality if the workflow isn't intelligently routed.
Terse coding forces models to output minimal code to save output tokens, but does nothing to solve inefficient tool calling.
Speculative decoding uses a smaller draft model to speed up a larger model's text generation, optimizing inference speed while failing to address bloated agent architectures.
These efforts fail because they optimize the engine while ignoring the transmission. They do not look at the orchestration layer, leaving underlying architectural inefficiencies unresolved.
Unpacking the harness: the levers of efficiency
The harness is the orchestration layer that routes, formats, and turns the underlying LLM into a working system.
The core levers of harness optimization include system prompt caching, interaction history compaction, tool management, retrieval strategies, and error management. These are the most accessible intervention points for engineering teams looking to improve AI performance.
As the Writer researchers note in the study: “If the harness is the layer that composes model calls into work, it is also the layer that sets the price of work.”
Historically, developers have treated the harness as disposable glue code designed simply to connect an API to a user interface. The study signals that the harness must now be treated as a first-class object: a primary software artifact that requires its own testing, versioning, and rigorous design.
For enterprises, this reframes the "own-versus-rent" decision.
"Enterprises spend months on model evaluations and then rent their orchestration off the shelf — which means they're optimizing the smaller lever and outsourcing the bigger one," AlShikh said. "Whoever owns the harness owns your unit economics, and an open framework tuned for demos is not tuned for your invoice."
Inside the experiments
To isolate the impact of the orchestration layer, the researchers ran experiments on six foundation models spanning multiple vendors and weight classes: Claude Sonnet 4.6, Gemini 3.1, Gemini Flash 3.5, Qwen 3.6, GLM 5.1, and Writer’s own model, Palmyra X6.
Their experiments compared a frozen, conventional production agent loop against the finished Writer Agent Harness on the same 22 locked enterprise tasks, spanning capabilities like grounding and retrieval, multi-step workflows, tool use, and content generation. By holding the models and tasks constant, they could isolate the effects of the orchestration layer itself.
The optimized harness drove a significant drop in costs, cutting the blended cost per task by 41%, from 21 cents to 12 cents. This was largely achieved by slashing token consumption, with the number of tokens per task falling 38%, from 14.2k to 8.8k.
The harness is designed to delegate tasks like search to specialized sub-agents. A sub-agent receives only the tool and the specific query it needs, retrieves the exact data, and returns a capped, clean summary to the main agent — keeping the primary context window from filling up with raw search results.
Task success rates held steady even as token use fell — moving from 78% to 81%, a gain the researchers describe as directional rather than statistically significant at their sample size, meaning quality didn't suffer even as costs dropped.
End-to-end task latency also dropped significantly, reducing the median wall-clock time by 44%, from 48 seconds to 27 seconds, due to prompt caching and the elimination of dead-end reasoning loops.
However, the researchers also found limits to multi-agent orchestration. Smaller models like Gemini Flash 3.5 and Qwen 3.6 scored well below a usable reliability threshold on sub-agent delegation tasks (0.45 and 0.42, respectively) — the capability simply isn't dependable yet on lighter-weight models.
Sub-agent orchestration only crossed a usable reliability threshold on the two strongest models tested: Writer's own Palmyra X6 (0.86) and Claude Sonnet 4.6 (0.85).
The developer’s playbook: actionable takeaways and tradeoffs
The findings from the study translate into a playbook for enterprise developers building agentic workflows at scale. The first step is to implement what AlShikh calls the "Two-Zone Prompt" and "Context Offloading."
Structure for system prompt caching (The Two-Zone Prompt): Modern LLM APIs offer prompt caching, but developers must structure their payloads correctly to trigger it. Developers must separate the "stable zone" from the "volatile zone." Place static, unchanging elements (e.g., core rules, large tool schemas, and standard operating procedures) at the top of the prompt. Dynamic elements, such as the specific user query or recent conversational task state, must be appended at the bottom. This ordering allows the harness to reuse the cached prefix across hundreds of calls. "That single separation makes prompt caching actually work and stops you from re-paying for the same instructions on every one of an agent's thirty steps," AlShikh said.
Manage context with Context Offloading: Avoid context stuffing, where every turn of a loop is appended into a monolithic prompt until the window maxes out. Instead, move history and intermediate artifacts out of the window into retrievable storage, and pull back only what the current step needs. If possible, delegate tasks to single-purpose sub-agents to avoid context bloat. As AlShikh points out, "the biggest line item in agent spend isn't reasoning — it's re-sending things the model has already seen."
Build resilient loops and redefine KPIs: Unmanaged agent loops drain API budgets rapidly. Teams must begin tracking Completions Per Million tokens (CPM) to understand their true task costs, but the harness itself must contain physical guardrails. "The core principle is that you never ask the model to police its own spending," AlShikh said. "The fence has to live below the model, in code, on your side of the API." This requires three hard checks:
Hard per-task token budgets: The run terminates when the budget is spent, no exceptions.
Generation fencing: Caps on steps, tool calls, and recursion depth to stop non-converging agents.
Failure-spend governance: Cap what a run can spend after its first failed validation so a failing task doesn't become your most expensive task.
Avoid unnecessary complexity: Optimizing the orchestration layer comes with engineering overhead. If you're in the prototyping and exploration stage, that overhead isn't justified — iterate fast with a strong model and a light harness. Once you're scaling to millions of requests a day, the savings from harness optimization become substantial.
However, teams must be aware of "harness leverage." Adding structural scaffolding requires the model to hold and obey that context. If a model is too small, it will spend its limited capacity parsing the scaffolding instead of doing the task, causing accuracy to drop and tokens to rise. The rule for adding complex orchestration features is strictly mathematical: "If a feature adds more coordination tokens than it removes task tokens for that specific model, cut it," AlShikh said. "Nothing in the harness is free."
The future of the enterprise harness
The era of tokenmaxxing and treating context windows like bottomless buckets is coming to an end. Throwing more compute at poorly designed systems is not a viable strategy for companies that need to demonstrate a return on their AI investments.
As foundation models evolve to absorb planning, tool selection, and multi-step reasoning natively into their weights, the role of the harness will shift from compensating for model weakness to enforcing enterprise policy.
"What never moves into the model is the 'allowed': budgets, permissions, data boundaries, audit trails, deterministic kill-switches," AlShikh said. "Five years from now, the harness will be thinner but more important. There will be less scaffolding and more governance. However capable the model gets, someone external to it still has to define what it may spend, see, and touch. That layer belongs to the enterprise, and it should never be rented."
A single AI agent conversation can look flawless scored on its own and still point to a broken product. That gap is driving a shift in how enterprises evaluate agents, away from scoring individual traces and toward comparing cohorts of users against a baseline.
At VB Transform 2026, Harrison Chase, CEO of LangChain; Hui Zhang, CTO and co-founder of Conviva; and Emmanuel Turlay, director of engineering at CoreWeave, described that shift, along with a parallel move toward cheaper, narrower judge models.
Agent-as-judge — judging one AI agent's output with another — hasn't replaced LLM-as-judge, which Chase said remains the default. The larger tension, Zhang said, is between automated judging, whether by LLM or agent, and human review.
"You have scalable but ungrounded, whether it's agents as judge or LLMs as judge, you grade the outcome, you grade the work. It still is very difficult to ground it and then you use humans and that's just not scalable," Zhang said. "The whole industry is facing this, which poison you want to pick."
Evaluation criteria now function as the product spec
That gap — a conversation that scores well but still signals a broken product — is what teams try to close by building an exhaustive evaluation suite before they ship anything. Chase said that doesn't work.
"We sometimes see teams that have almost eval paralysis," Chase said. "They're like, this is an eval set, I can't launch it. The best teams launch and then iterate."
Chase framed evaluation criteria as a living specification, not a one-time test suite: a product requirements document — the standard software-development spec for what an application should do. "Evals are like the new PRD," he said. "They define what your agent should and shouldn't do."
Turlay described hitting the same failure from a different angle. "I was trying to reach 100% coverage for my tests, and I still had bugs in production," he said — a test suite that looked complete but still missed what mattered, the same gap Chase was describing with evals.
Broad, always-on monitoring, he said, catches more real failures than an exhaustive pre-launch test suite. Teams should set up wide online checks first, use those to identify failure classes as they occur, then build a targeted offline evaluation set around the problems that surface.
Why scoring traces one at a time is a mistake
Even a well-built evaluation process can still score the wrong thing. Zhang's objection is to how most teams run evaluation: sampling traces, whether 50 of them or a full population, scoring each in isolation. That approach misses a signal that only shows up when comparing cohorts of users against a baseline, a method Zhang calls contrastive analysis.
Zhang illustrated it with a retail example: a shopper asks an agent for a running shoe ahead of a half marathon, the agent asks qualifying questions, and the shopper buys a shoe. Scored individually, that interaction looks fine. But the clarification ratio, how many follow-up questions an agent asks before completing a task, came in three times higher than baseline for that shoe category across the full user population. A second metric, how often shoppers finished their purchase outside the conversation, was five times higher than baseline for the same category.
Neither number is visible from a single trace. Both point to a debuggable, category-specific problem. Zhang said the industry also lacks a second data source: what happens before, between and after the conversation, not just the trace itself.
Sizing the judge to the job
Once contrastive analysis flags which category is actually broken, the next problem is what watches for it going forward — and at what cost. Turlay's rule was to start with the most capable model available to prove a task is solvable, then work down. If it can't be done with a top-tier model, he said, it won't work with a smaller one. Once a pattern proves viable, teams can sample a fraction of traffic instead of judging every interaction, and move simpler tasks like binary classification to smaller open source models.
LangChain took that further, fine-tuning its own model to detect when a user believes the agent made a mistake, a signal Chase calls perceived error. "The model we fine-tuned was a Qwen model," he said, referring to Alibaba's open source family. Combining hand labeling with distillation, the result performed well. "Same as [Claude]Sonnet, for, depending on how we served it, either 10 to 100x cost reduction," Chase said.
Not every guardrail needs a model. Chase pointed to Claude Code's own guardrails as proof: regexes, the common programming technique for finding and validating patterns in code. "A lot of the guardrails they had were just regexes," he said. "They weren't small LLMs, they were just regexes."
LLM-as-judge doesn't mean human-in-the-loop disappears
The bigger question is whether using LLM as a judge removes the need for a human in the loop.
Turlay pointed to accountability, drawing on his prior work at a self-driving car company. His team compressed data intake and retraining into a two-week cycle for shipping a new model to the car. Even then, someone still had to sign off.
"I felt confident on behalf of the company to say this model should go into the car," he said. The same logic extends to legal, finance and healthcare. "Before we can remove a human to say, I endorse this and I take responsibility legally for it, it's going to be a while before agents can do that on their own."
Zhang agreed a human has to remain the guardian on corner cases, even as automation eventually runs at a scale that beats individual human accuracy — machines can see more at the pattern level.
Chase went further: that human check isn't just a safety net. "Human in the loop is really important for building trust in how these agentic systems work, and also really important for memory and learning from systems," he said. "There has to be interactions in order for the system to learn."
Zillow, the real estate technology company, doesn't get one conversation with its customers. They move from a phone screen to a loan officer to a real estate agent, sometimes over months or years, and expect the context to follow them. A single chatbot could never carry that thread.
At VB Transform 2026, Zillow SVP of Engineering Toby Roberts and Glean co-founder and CEO Arvind Jain described how they built AI architecture meant to carry context across that entire journey — and why context, not raw data, turned out to be the harder problem to solve. Zillow's products touch roughly 80% of U.S. real estate transactions each year, and the company has been using AI long before ChatGPT existed.
"We pretty quickly identified that we were going to need a persistent context layer that was going to meet our customers and the professionals wherever they were," Roberts said.
Data was never the hard part
Roberts said Zillow's AI effort started where most enterprise AI efforts start, with the data itself.
"We started with a large push around making sure our data did have the right foundation," Roberts said. That meant a data mesh approach, clear data lineage and a governance structure with permissions and identity attached to the data itself.
None of that turned out to be the hard problem. The hard problem was building something that remembered where a customer was in their journey and carried that forward, no matter which surface they showed up on next.
"This context layer has to live to be able to support you where you are at any given point in your journey," Roberts said. Zillow chose to own that layer itself rather than depend on a single external chat interface, a decision Roberts said the team reached quickly once it looked at the shape of a real transaction rather than a single conversation.
Why Zillow built its own architecture, and where Glean fits into it
Zillow built its own harness rather than route customers through a single model API. The team drew on 20 years of machine learning history behind products like Zestimate, leaning into smaller, task-specific fine-tuned models instead of one general-purpose model.
Internally, that harness runs alongside Glean. Roberts said Zillow now has thousands of Glean agents in production, handling repetitive tasks with tens of thousands of executions across the company. Glean's pitch, per Jain, is centralizing that integration work once, through the Glean MCP gateway, rather than letting finance, legal and marketing each rebuild their own connections to the same systems.
That centralization is also a cost lever. Jain pointed to two mechanisms: model routing, which sends most tasks to smaller, cheaper models instead of defaulting to frontier models, and precomputed context, which avoids an agent burning tokens assembling its own context from scratch.
"Claude is also very slow because the first part of assembling that context actually takes forever," Jain said. Routing that request through Glean instead, he said, can cut token consumption by as much as half.
What Zillow and Glean's approach means for enterprises
Across data, cost and permissions, the session offered a few practical takeaways for enterprises building agentic AI on their own systems.
Build the measurement baseline before the AI push, not after. Roberts said Zillow's ability to credibly attribute a 40% increase in shipped code to AI adoption rests on a DORA metrics baseline the team put in place years earlier, not on the AI rollout itself.
Centralize context once instead of letting every team rebuild it. Jain's core argument for Glean's platform is that duplicated integration work across finance, legal and marketing teams is a hidden cost most enterprises haven't accounted for.
Don't assume permission inheritance is enough for regulated data. Even with a permissions-aware context platform in place, Zillow layered hard rules and a standing compliance check on top for its most sensitive categories, rather than trusting the architecture to handle it automatically.
Treat context as a cost lever, not just a capability. Model routing and precomputed context were the two mechanisms Jain pointed to for cutting AI spend, both aimed at reducing wasted token consumption rather than adding new capability.
"Models by themselves are not enough to bring automation with AI inside your enterprise," Jain said. "You do have to connect it with your enterprise context."
The enterprise technology ecosystem is caught in a costly cycle. Over the past two years, millions of dollars have been funneled into generative AI pilots, yet many of these initiatives stall out before ever reaching a live production environment.
When a project fails, the immediate instinct of technical leadership is often to blame the model: The context window was too restrictive, the latency was too high, or the reasoning capabilities simply were not there.
But as data engineers building the scaffolding for these systems, we often see a different reality: The model receives the blame, but the pipeline usually contains the root cause. Production gen AI rarely fails because of model limitations alone. More often, it fails because the enterprise data foundation underneath it is fundamentally unready.
This is what I call the 'Cleanup Trap': The false belief that an organization can pipe fragmented, inconsistent, and ungoverned legacy data into a large language model (LLM) orchestrator and simply “clean it up” or patch it at the retrieval layer.
The mirage of the retrieval layer
In a standard retrieval-augmented generation (RAG) architecture, the retrieval layer is tasked with pulling relevant business context to ground the model’s responses. Because modern frameworks make it simple to stand up a vector database and a basic embedding pipeline, leadership often assumes that the data engineering problem is solved.
It is not.
When an embedding model receives raw, unvalidated data directly from operational silos, the resulting vector space inherits the structural noise, duplicate records, and conflicting states present in the source systems.
If the core data pipeline suffers from silent degradation — schema drift, missing fields, delayed change-data-capture (CDC) synchronization — that degradation cascades directly into the vector store. An AI model cannot accurately synthesize customer intelligence if the data pipeline behind it is serving stale, contradictory profiles across disparate storage layers.
No amount of prompt engineering, semantic reranking, or vector hyperparameter tuning can compensate for a broken ingestion pipeline. If the foundation is compromised, the downstream application will hallucinate, expose unauthorized context, or fail to deliver deterministic value.
Shifting from ad-hoc patching to programmatic guardrails
To break out of the 'Cleanup Trap,' enterprise data teams must stop treating data quality as a post-processing step. They need to treat data readiness for AI with the same rigor they bring to traditional transaction processing.
This requires a deliberate architectural shift toward zero-trust data ingestion, structured validation frameworks, and automated anomaly detection before data ever reaches an AI orchestration layer.
1. Harden the ingestion pipeline
Data quality checks cannot exist as a nightly batch afterthought. If an enterprise AI application relies on real-time data to assist users, validation must happen inline.
Teams should implement explicit schema validation checks at the earliest ingestion point, such as the streaming ingress layer or the bronze landing layer of a medallion architecture. If an upstream operational database mutates a schema without warning, the pipeline should quarantine anomalous payloads rather than allowing corrupted metadata to pollute downstream AI contexts.
2. Use multi-tiered algorithmic validation
Static row-count validation rules are insufficient for AI readiness. True data health requires a multi-tiered approach.
This means pairing structural verification — null checks, type conformance, and schema validation — with statistical profiling to monitor for data drift. Tracking metric deviations across feature distributions helps ensure that historical context remains stable over time.
If a pipeline suddenly processes an unexpected spike in empty string variables or structurally deviant fields, automated alerts should trigger an immediate pause before vector database updates continue.
3. Decouple security and compliancemfrom the model
An LLM should never be the arbiter of data access control. Trying to enforce row-level security or personal data filtering through system prompts is a compliance risk.
Security must be managed within the data infrastructure tier. Enterprise data foundations should enforce strict access controls, tokenization of sensitive identifiers, and rigorous lineage tracing before information is indexed into vector stores or passed into an agent’s context window.
Technical alignment: A pragmatic blueprint
For technology leaders mapping their infrastructure roadmaps, AI readiness requires evaluating data pipelines against a strict operational checklist.
Can you trace a flawed AI response back to the exact pipeline execution, source record, and transformation step that produced it?
Does your data lake architecture have a programmatic mechanism to segment and quarantine corrupted or non-compliant data before it reaches production feature stores?
Are your operational systems and AI-facing vector databases tightly synchronized, or are your agents making automated decisions based on outdated snapshots?
These questions matter because production AI is not just a model deployment problem. It is a data reliability problem.
Building for the production era
The honeymoon phase of gen AI experimentation is ending. Enterprise leaders are demanding measurable, predictable, and secure business outcomes from their AI investments.
If an organization wants to transition from isolated, impressive-looking demos to resilient, production-grade AI systems, it must redirect its focus. Stop looking exclusively at the model tier.
The real competitive differentiator is not only the LLM an organization chooses. It is the engineering discipline, data governance, and pipeline resilience of the infrastructure built to feed it.
In the production era of AI, data engineering is no longer a backend function. It is the control plane for enterprise intelligence.
Hugging Face’s incident response team first turned to frontier AI models to analyze a breach of the company’s production infrastructure, and the models refused to help. Commercial safety guardrails built to stop attackers blocked every forensic query because they treated the IR team’s real exploit data the same way they would treat a live attack.
The attacker, an autonomous AI agent running the campaign end to end, moved laterally across the Hugging Face infrastructure for a weekend, undetected and unstopped.
Security leaders are quick to recognize the pattern and diagnose what went wrong. “I’ve seen versions of this during red-team exercises and internal security testing, but this is one of the first high-profile examples where it materially affected real incident response,” said Merritt Baer, senior adviser to Andesite, G2I, and AppOmni and former Deputy CISO at AWS.
None of this is unique to Hugging Face, Baer said. “Commercial frontier models optimize for preventing misuse. They generally have no cryptographic or organizational way to determine whether the person asking ‘analyze this malware’ is an incident responder or the malware author.”
A malicious dataset opened two code-execution paths
On July 16, Hugging Face disclosed that an autonomous AI agent system had compromised its production infrastructure, gaining unauthorized access to a limited set of internal datasets and several service credentials. The company verified that its software supply chain was clean and found no evidence of tampering with public models, datasets, or Spaces.
Hugging Face is still assessing whether the intrusion touched any partner or customer data and says it will contact affected parties directly as required. But few enterprise threat models had accounted for the attacker Hugging Face faced. An autonomous agent ran the entire campaign from initial access through credential harvesting. No human guided it.
The entry point was a malicious dataset. When the data-processing pipeline ingested it, the dataset triggered code execution in two ways, through a remote-code loader and through a template-injection flaw in dataset configuration files. No admission gate screened the file before it reached a processing worker, the compute job assigned to each dataset. Initial access came through the data pipeline itself, a route that worked because most enterprise security teams treat the data feeding their pipelines as trusted input rather than an attack surface.
Worker isolation did not hold. From that first foothold, the agent broke out onto the node running the workload, then harvested cloud and cluster credentials scoped broadly enough to reach multiple internal clusters, all of it inside a single weekend. Hugging Face described the agent framework as executing thousands of individual actions through a swarm of short-lived sandboxes, with self-migrating command-and-control staged on public services. The disclosure adds that the framework appeared to be built on an agentic security-research harness, which would put tooling designed for red-team work behind a live intrusion.
Why the defenders’ queries looked like attacks
Investigators reconstructed more than 17,000 recorded events using AI-driven analysis agents of their own.
First attempts at the log analysis ran on frontier models behind commercial APIs. Defenders’ steps included submitting real attack commands, exploit payloads, and command-and-control artifacts for classification, but safety guardrails blocked the requests outright.
Baer traced the block to the prompts themselves. “The same prompts that are most valuable during an active intrusion, shell commands, exploit chains, credential dumps, persistence mechanisms, lateral movement, are exactly the prompts most likely to trigger safety systems,” she told VentureBeat. “As AI becomes embedded in security operations, this becomes an operational resilience issue rather than merely a model policy issue.”
The forensic analysis finished on GLM 5.2
GLM 5.2, an open-weight model deployed on Hugging Face’s own infrastructure, took the job the commercial APIs refused. No attacker data left the company’s environment. “This experience points to a gap worth planning for,” the company wrote in its disclosure. Hugging Face does not know which model powered the agents. It could have been a jailbroken hosted model or an open-weight model running without restrictions. Either way, the disclosure continued, “the attacker was bound by no usage policy, while our own forensic work was blocked by the guardrails of the hosted models we first tried.” Hugging Face drew that line itself, writing that the experience is not an argument against safety measures on hosted models and that it is sharing the feedback with the providers concerned.
What authenticated trust changes
The industry, Baer argued, needs to move past treating AI safety as a content moderation problem. “Security operations require something different. Authenticated trust.” Instead of asking whether anyone should receive an answer, the question becomes whether an authenticated security team, operating under enterprise controls, should receive it. “The model shouldn’t only understand what is being asked. It should understand who is asking, why, and under what governance.”
“Organizations already build contingency plans for cloud outages, identity provider failures, or EDR failures,” Baer wrote. “AI assistants are becoming another dependency.”
Her advice on IR playbooks was blunt. “A mature incident response plan should assume that during a severe incident, commercial AI APIs may refuse requests, API rate limits may become unavailable, internet connectivity may be impaired, and data governance rules may prohibit uploading forensic evidence externally.” The lesson, she wrote in her emailed answers, “isn’t ‘don’t use commercial models.’ It’s ‘don’t make them a single point of failure.’”
AI-enabled attacks rose 89% year-over-year
Autonomous AI-driven attacks are not limited to AI platforms. CrowdStrike’s 2026 Global Threat Report documented AI-enabled adversary operations increasing by 89% year over year, with average breakout times falling to 29 minutes. Enterprises running AI workloads in production with agentic access to their pipelines face similar exposure.
Six control domains determined the blast radius and recovery speed at Hugging Face. Each one maps to a concrete action security leaders can take before the next autonomous-agent breach arrives.
AI Pipeline Breach Response Playbook
Control Domain
What Broke
Monday Action
Dataset admission controls
Two code-execution paths were exploited. No admission gate validated the dataset before it reached a processing worker. The data pipeline became the initial access infrastructure.
Require sandbox execution and static analysis of all datasets before they reach workers. Block remote-code loaders and template-injection paths by default. Audit for any path granting code execution to untrusted content. Report to the board as a supply-chain risk.
Worker-to-node privilege boundaries
Worker isolation failed to prevent escalation to the node. The agent gained cluster credentials because the workload-infrastructure boundary was never enforced at container runtime.
Enforce hard privilege boundaries between workers and nodes. Deploy container runtime security to prevent workload escape. Audit whether workers can reach node-level APIs or credential stores. Include in the next penetration test scope.
Credential exposure
Cloud and cluster credentials harvested after node access. The scope was broad enough for lateral movement across multiple clusters over a weekend.
Rotate credentials on a scheduled cadence and after any anomaly alert. Scope to the minimum cluster and service. Deploy monitoring that flags access from unexpected nodes at machine speed. Map blast radius for board reporting.
Machine-speed detection
Thousands of actions through short-lived sandboxes with self-migrating C2. AI-assisted anomaly detection surfaced the campaign after a weekend of lateral movement, per the disclosure.
Calibrate detection for machine-speed patterns. Ensure high-severity alerts page responders in minutes, regardless of time. Audit SIEM rules for detecting thousands of short-lived executions within a single hour.
Private AI forensic capacity
Commercial APIs blocked forensic analysis. Guardrails screened query content, never analyst identity. Investigation ran on GLM 5.2 privately.
Deploy a capable open-weight model on private infrastructure before an incident. Test against real forensic workflows. Ensure IR playbook includes fallback for when commercial APIs refuse. Document gap for cyber insurance.
Autonomous-agent threat modeling
The campaign matched the forecast agentic-attacker scenario, but no threat model had operationalized it. LLM powering the agent is still unknown.
Add autonomous AI agents as a distinct adversary class with machine-speed decision cycles. Run tabletop at agent speed. Present results to the board as evidence that timelines need recalibration. Include in the cyber insurance application.
The board question is operational resilience
“The question for directors is simple. What happens if one of our critical security tools becomes unavailable during the exact moment we need it most?” Baer framed that as operational resilience, not AI policy.
She would have boards take that framing straight to management and press for specifics. “Have we actually exercised that fallback during tabletop exercises? How quickly can we switch during an incident?” Procurement needs to change alongside governance, starting with the questions buyers ask. Security teams evaluating AI vendors should ask about their process for authenticated incident responders, whether enterprise customers receive different handling during verified incidents, and whether models can be deployed privately. “Those questions belong alongside uptime, privacy, and compliance,” Baer said.
“The biggest takeaway isn’t that safety guardrails are ‘bad.’ They’re doing what they were designed to do,” she argued.
Her larger point is that the threat model itself has changed. “For decades, defenders had better tools than attackers because they operated inside trusted enterprise environments. With foundation models, both sides increasingly use the same capabilities, but one side is constrained by enterprise governance, policy, compliance, and safety controls, while the adversary simply downloads an uncensored open-weight model and keeps going. That’s a new kind of asymmetry,” she added. “The organizations that handle it best won’t necessarily be the ones with the most powerful AI. They’ll be the ones that architect AI as a resilient security capability rather than a single cloud service.”
Hugging Face has contained the intrusion, rebuilt compromised nodes, rotated credentials, and reported the incident to law enforcement. The company recommends that all users rotate access tokens and review recent account activity. Mid-incident, Hugging Face found out whether its own AI tooling would be available, and the first answer was no. Security leaders running AI in production should find out in incident response planning instead, before an autonomous agent forces the test.
The organizations losing confidence in AI are the ones most likely to get it right.
Six months ago, 40% of IT leaders described their organizations as mature in AI deployment. Today that number is 23%. Before you read that as a setback, consider what it actually reflects.
We recently surveyed 800 IT leaders across the U.S. and U.K. for our Q3 2026 trends report, and the data tells a consistent story: the organizations revising their self-assessment downward are overwhelmingly the ones that have moved AI agents from pilots into production. They’re not losing faith in AI. They’re running into the problems that only show up when agents are doing real work in real systems, and they’re being honest about what they found.
That kind of honesty is harder to come by than it sounds, and it matters more than the confidence number itself.
Deployment was the easy part
84% of organizations plan to expand AI use in IT operations over the next 6 to 24 months, so the drop in confidence isn’t a retreat. What it reflects is a more accurate picture of what production actually requires.
In a pilot, an AI agent does one thing in a controlled setting. In production, it accesses real systems, makes decisions that affect real workflows, and operates continuously, often without a human in the loop. The governance infrastructure that entails is materially different from what it took to get the pilot working. Most organizations built enough to ship. Fewer built enough to scale.
The IT leaders revising their self-assessment are confronting questions they didn’t have to ask at the pilot stage: Can we see every agent running in our environment? Do we know what each one can access? If an agent behaved unexpectedly last week, how long would it take to find out? For most organizations, at least one of those answers is uncomfortable.
The gap between perception and reality is where risk accumulates
The graphic above captures the structural problem. Across confidence, governance, and autonomy, the same pattern holds: deployment is moving faster than the controls built around it.
The organizations that have closed this gap share specific characteristics. They’ve consolidated their IT environments rather than adding tools to solve each new problem, because every additional platform creates another place where agent identity, access, and accountability can go unmanaged. They treat AI agents as governed identities rather than tolerated shadow processes. And they measure what AI actually produces, not just what it deploys.
The payoff is tangible. Organizations in the top tier of our maturity model are five times more likely to report no barriers to expanding their AI agents than the average organization. They are not more cautious about AI. They are more confident in it, because they built the foundation that makes confidence earned rather than assumed.
The governance gap has a specific shape
The hardest problem in enterprise AI right now is not capability. It is accountability, and the data makes the specific failure point clear: non-human identity governance is the least adopted AI security practice we measured, in place at just 21% of organizations.
Non-human identities now outnumber human users in 83% of organizations, and that population is growing fast. Yet most of those identities exist without the governance structures that every human employee has as a matter of course: no formal record, no named owner, no defined scope of access, no offboarding process when their purpose expires. They keep running. They keep accessing systems. They keep accumulating permissions. We call these Zombie Agents, and they are the service account problem of the AI era, operating at machine speed and in every department.
The accountability gap is where real risk lives. When a human employee takes an action, there is an implicit accountability chain. When an autonomous agent takes an action, that chain breaks unless it has been deliberately engineered. Most organizations have not yet engineered it, and the gap between the autonomy agents are being granted and the oversight structures in place to manage them is widening every month.
What the confidence drop is actually telling us
When AI maturity confidence was uniformly high across the market, that was worth worrying about. It meant most organizations hadn’t yet run into the hard parts. A selective drop, concentrated among organizations actively running agents in production, means the market is developing a more accurate picture of what AI operations genuinely require.
The organizations recalibrating are doing the work that makes long-term AI adoption possible: building identity infrastructure that covers agents alongside humans and devices, unifying the environments where governance needs to apply, and measuring outcomes rather than just counting deployments. They haven’t lowered their ambitions for AI. They have raised their standards for what it means to run it responsibly.
84% of organizations plan to expand AI use over the next two years. The ones that will do it well are honest enough, right now, to admit what they haven’t yet built.
JumpCloud’s Q3 2026 AI Readiness Research report (n=800 IT leaders, U.S. + U.K.) is available here. The report covers AI agent deployment stages, identity governance gaps, IT unification benchmarks, and budget realism across mid-market and enterprise organizations.
Rajat Bhargava is CEO and Co-founder at JumpCloud.
Sponsored articles are content produced by a company that is either paying for the post or has a business relationship with VentureBeat, and they’re always clearly marked. For more information, contact sales@venturebeat.com.
Capital One on Thursday released VulnHunter, an open-source, agentic AI security tool that scans source code for exploitable vulnerabilities, maps out how an attacker would reach them, and proposes targeted fixes — all before a single line ships to production. The tool, built internally and now available on GitHub under an Apache 2.0 license, is one of the most ambitious attempts by a major financial institution to turn offensive AI capabilities into a public defensive resource.
At a time when security teams are facing a rising tide of new AI threats, Capital One's decision to open-source the tool reflects an effort, according to CISO Chris Nims, to address "an increasingly brief window before sophisticated, next-generation AI attack capabilities become affordable and accessible to virtually every adversary."
Capital One is not simply releasing another vulnerability scanner. VulnHunter introduces what the company calls an "attacker-first forward analysis" — a workflow in which the tool begins at the points where a real adversary would enter a system, such as APIs, network messages, or file uploads, and reasons forward through the application's logic to determine whether an exploit path actually survives the code's existing defenses. Conventional scanners typically work in reverse, flagging a dangerous-looking code pattern and then searching backward for a hypothetical attacker. That approach, security practitioners widely acknowledge, buries engineering teams under avalanches of false positives.
VulnHunter attacks that problem head-on with a second innovation: a built-in "falsification engine" that tries to disprove its own findings before a developer ever sees them. After the tool surfaces a potential vulnerability, a structured reasoning workflow hunts for logical gaps, unsupported assumptions, and conditions that would prevent the attack from succeeding. Only findings the engine fails to rule out reach a human reviewer — and when they do, VulnHunter delivers not just an alert but a full explanation of the exploit path and a proposed code fix ready for engineering review.
The tool currently runs on Anthropic's Claude Opus 4.8 model inside a Claude Code environment, though Capital One says the framework has the potential to work across other foundation models and coding harnesses.
Why Capital One is giving the tool away
Asked why Capital One decided to open-source a tool this consequential, Nims pointed to the communal nature of the problem.
"We felt an imperative to open-source VulnHunter because modern software supply chains are very connected, and the scale of the AI threat is larger than any single organization," Nims told VentureBeat. "Securing software and our digital environments is a shared foundation that benefits developers, enterprises, and the people who depend on the systems we all build. The defensive tools to address this reality need to be just as widely distributed, tested, and improved as the codebases they protect."
"Rather than wait," he added, "we decided that the right response was to build a product that is purpose-fit for today's complex security landscape, and put it into the hands of defenders everywhere."
Why Capital One believes open-sourcing VulnHunter strengthens everyone's defenses
The release nonetheless arrives against a backdrop the company knows well. On July 19, 2019, Capital One disclosed that an outside individual — later identified as a former Amazon Web Services employee named Paige Thompson — had gained unauthorized access to names, addresses, self-reported income, Social Security numbers, and linked bank account numbers belonging to credit card customers and applicants. The breach, which Capital One says occurred on March 22 and 23, 2019, was discovered only after an external security researcher flagged a configuration vulnerability through the company's Responsible Disclosure Program on July 17 of that year.
The damage was sweeping. Approximately 100 million people in the United States and 6 million in Canada were affected. Roughly 140,000 Social Security numbers, about 80,000 linked bank account numbers, and approximately 1 million Canadian Social Insurance Numbers were compromised. The FBI arrested Thompson, and the government stated it believed the data had been recovered with no evidence of fraud. But the reputational and regulatory toll was enormous.
In August 2020, the Office of the Comptroller of the Currency fined Capital One $80 million, finding that the bank had failed to adequately identify and manage risks as it migrated significant technology operations to the cloud. As Reuters reported at the time, the OCC's consent order cited insufficient network security controls, inadequate data loss prevention measures, and a board that failed to hold management accountable when internal auditing surfaced problems. The OCC also ordered Capital One to overhaul its operations and submit new cybersecurity plans for regulatory review.
CyberScoop at the time called the incident "a cautionary tale for companies rushing to embrace new tech." Capital One's own CEO, Richard D. Fairbank, acknowledged the gravity of the moment. "While I am grateful that the perpetrator has been caught, I am deeply sorry for what has happened," Fairbank said at the time. "I sincerely apologize for the understandable worry this incident must be causing those affected and I am committed to making it right."
Inside Capital One's decade-long open-source strategy — and what VulnHunter adds to it.
What followed was not a retreat from technology but a doubling down — with security explicitly at the center.
Capital One began releasing open-source projects in 2014 and declared itself an "open-source first" company in 2015 as part of a broader technology transformation that began over a decade ago. The company has continued to invest in software supply chain security, open-source governance, and AI-driven defense. In August 2022, Capital One joined the Open Source Security Foundation as a premier member, earning a seat on the organization's Governing Board. Chris Nims, then EVP of Cloud & Productivity Engineering, framed the move as a natural extension of the company's operating philosophy. "As a highly-regulated company, we are seasoned in managing compliance and governance and advocate for standardization, automation and collaboration," Nims said in the OpenSSF announcement.
Behind that public commitment lay a substantial operational apparatus. Capital One's Open Source Program Office, now in its third iteration, manages open-source usage, contributions, and community building across the enterprise. The company has released more than 40 open-source projects and has made thousands of contributions to external open-source projects it depends on, according to the company. Those efforts address not just code dependencies but the entire software development lifecycle — DevSecOps tools, infrastructure, and the collaborative environments, both internal and external, that shape how software gets built and shipped.
VulnHunter is the most consequential product of that multi-year effort — and the release reflects a calculation increasingly common among large enterprises: that in security, giving away the tool is cheaper than fighting alone. "At the end of the day our goal is to make this product as broadly accessible as possible," Nims said.
The company argues that modern software supply chains are so deeply interconnected that a single vulnerability in a widely used open-source component can cascade across thousands of enterprises simultaneously. Proprietary defenses, no matter how sophisticated, cannot address a problem that is fundamentally communal. By releasing VulnHunter under a permissive license, Capital One invites the global security research community to stress-test, extend, and improve the tool — effectively crowdsourcing its own defense infrastructure while strengthening the broader ecosystem.
Inside VulnHunter's three-stage AI engine for finding exploitable code
For engineering leaders evaluating VulnHunter, the technical architecture is where the tool's ambitions become concrete. The workflow unfolds in three distinct stages.
In the first stage — attacker-first forward analysis — VulnHunter begins at the points where an external adversary would interact with a system: API endpoints, network message handlers, file upload interfaces. From each entry point, the tool reasons forward through application logic, tracing data flows, transformations, and internal security checkpoints to determine whether an attacker can actually reach a dangerous code path. This approach mirrors how a skilled penetration tester would probe a system, but automates the process at a scale no human team could match.
The second stage is where VulnHunter departs most sharply from conventional scanners. After identifying a potential vulnerability, the falsification engine runs a structured reasoning workflow designed to disprove its own conclusion. It searches for assumptions that do not hold, logical gaps in the exploit path, and environmental conditions that would prevent an attack from succeeding. Findings that fail this internal challenge are discarded before any developer sees them. Capital One's explicit goal is to shift the developer's burden away from triaging false alarms — a perennial pain point that erodes trust in security tooling and slows development velocity.
In the third stage, vulnerabilities that survive the falsification engine trigger an evidence-backed remediation workflow. VulnHunter gathers supporting evidence across the codebase, maps the complete surviving exploit path, explains the defect and the specific capabilities an attacker would gain, and generates targeted code changes for engineering review. The output is not a generic advisory but a concrete, context-aware patch proposal.
Capital One says it validated VulnHunter internally before release, running it across thousands of repositories spanning tens of business areas. The company reports that the tool identified and remediated vulnerabilities with speed and efficiency that far exceeded what its teams previously achieved through manual triage.
Why AI-powered attacks are forcing banks to rethink traditional cyber defenses
VulnHunter arrives at a moment when the cybersecurity landscape is shifting beneath the feet of every enterprise. Capital One's announcement frames the urgency in stark terms: advanced AI models have "dramatically lowered the barrier for bad actors to discover and exploit vulnerabilities in software," and the window before sophisticated AI attack capabilities become affordable and accessible to virtually every adversary is shrinking rapidly.
"Safeguarding information is essential to our mission and our role as a financial institution," Nims told VentureBeat. "We have invested heavily in cybersecurity and will continue to do so to stay ahead of today's evolving threat landscape."
The company's own AI security researchers have been tracking these trends closely. At NeurIPS 2024 in Vancouver, Capital One's team presented research and curated a list of nearly 100 papers spanning LLM safety, adversarial resilience, jailbreak attacks, and synthetic data generation. The papers they highlighted — including work on multi-agent defense frameworks, automated red-teaming, and guardrail classifiers — paint a picture of an arms race in which offensive and defensive AI capabilities are co-evolving at breakneck speed.
Several of those research themes map directly onto VulnHunter's architecture. The falsification engine echoes the adversarial defense strategies explored in papers like "BackdoorAlign," which demonstrated that embedding a structured safety mechanism into a small number of training examples could recover a model's safety alignment without degrading performance. The attacker-first forward analysis reflects the philosophy of "WildTeaming," a framework that collects and analyzes real-world jailbreak attempts to build more resilient models. And VulnHunter's emphasis on minimizing false positives parallels the goals of "GuardFormer," a guardrail classifier that outperformed GPT-4 on safety benchmarks while running 14 times faster.
The thread connecting all of this work is a conviction that traditional, reactive security — monitoring networks, patching known vulnerabilities, responding to incidents after they occur — is no longer sufficient when adversaries can use AI to discover and exploit zero-day vulnerabilities at machine speed. The only durable defense, Capital One argues, is to find and fix the vulnerabilities in your own code before attackers find them first.
What Capital One's cloud security journey reveals about the entire banking industry
Capital One's cloud journey also illuminates a broader reckoning across financial services. When Capital One moved aggressively to Amazon Web Services in the mid-2010s, it was a rarity among major banks. Most financial institutions simply did not trust third parties to store their most sensitive data. Capital One's CIO at the time, Rob Alexander, publicly championed the cloud as more secure than the bank's own data centers — a claim that the 2019 breach complicated considerably.
The CyberScoop report from that period captured the tension within the industry. W. Patrick Opet, managing director of cybersecurity at JP Morgan Chase, described a cultural shift in banking from prioritizing traders to prioritizing developers: "Now, it's 'Focus on the developer, turn everything into code, and automate everything.'" Mark Nicholson, Deloitte's cyber leader for the financial industry, noted that the pressure to move quickly was exposing "weaknesses in the development methodology." And the breach itself was a reminder that even as Chase spent $600 million annually on cybersecurity, relatively simple vulnerabilities — like the Apache Struts bug that enabled the Equifax breach — could undercut massive investments in data protection.
Seven years later, the industry has largely followed Capital One into the cloud, and the security challenges have only intensified. The question is no longer whether to use cloud infrastructure but how to secure the software that runs on it. VulnHunter represents part of Capital One's answer to that question: rather than relying solely on network-level controls and perimeter defenses, push security directly into the code itself, at the moment it is written. The open-source release also carries implicit competitive pressure. If VulnHunter gains traction among developers and security teams, it could set a new baseline for what enterprise security tooling is expected to do — and force rival banks, fintechs, and cloud providers to match or exceed its capabilities.
Whether VulnHunter lives up to that ambition will depend on adoption, community engagement, and the tool's real-world performance against the increasingly sophisticated AI-powered attacks it was designed to counter. But the release itself tells a story that extends well beyond any single tool or any single company. In 2019, a misconfigured web application firewall — exploited alongside an overly permissive cloud access role — exposed the records of roughly 100 million Americans, drew an $80 million regulatory fine, and became one of the most widely cited cloud security incidents in the industry.
In 2026, the same institution is open-sourcing an AI-driven defense built for a new generation of threats — and betting that the best way to protect its own code is to help the entire industry protect theirs.
Elon Musk says robot fights are fun after watching China’s humanoid robot battleMon, 20 Jul 2026 08:34:01 +0000 A humanoid robot combat event organized by a Shenzhen robotics company has gone viral, even catching the attention of Tesla CEO Elon Musk. On July 19, Musk reposted a video from the event on social media, writing, “Robot fights are fun.” The footage features two EngineAI T800 full-size humanoid robots trading punches and kicks inside […]
Yimu Tech raises over RMB1 billion for robot tactile sensing and productionMon, 20 Jul 2026 08:09:59 +0000 Yimu Tech, a Chinese developer of tactile sensing hardware and software for embodied-intelligence systems, has completed a Series E financing round of more than RMB1 billion, bringing its valuation above RMB10 billion. The financing was jointly backed by multiple leading RMB funds, USD funds and industrial investors. The company is developing tactile sensing materials, chips, […]
China develops more than 400 humanoid robot products, accounting for over half of the global totalMon, 20 Jul 2026 05:59:25 +0000 China has developed more than 400 humanoid robot products, accounting for more than half of the global total, according to data released by the Ministry of Industry and Information Technology on July 20. The ministry also said Chinese quadruped robots accounted for close to 70% of global sales. [Xinhua, in Chinese]
China’s daily AI token calls reach 140 trillion, up more than 1,000-fold since early 2024Mon, 20 Jul 2026 05:48:41 +0000 China’s daily AI token calls reached 140 trillion by March 2026, up more than 1,000-fold from roughly 100 billion in early 2024, according to figures cited by China Academy of Information and Communications Technology deputy head Wei Liang in a CCTV Finance program preview published on July 18. Tokens are used to measure the amount […]
Bilibili showcases N.E.K.O., an AI companion that can interpret desktop content and initiate conversationsMon, 20 Jul 2026 05:44:02 +0000 Bilibili showcased its open-source “Catgirl Plan” AI digital-life ecosystem at WAIC 2026 in Shanghai on July 18. Its core product, Project N.E.K.O., is a proactive multimodal AI companion that can continuously observe a computer environment, interpret desktop content and initiate conversations. The system separates its front-end interface, AgentAI system and memory layer, while allowing users […]
Kimi K3 overwhelms capacity just days after launch, suspends new consumer subscriptionsMon, 20 Jul 2026 03:37:10 +0000 Moonshot AI has temporarily suspended new consumer subscriptions for Kimi after demand for its newly launched Kimi K3 model exceeded expectations and pushed its compute infrastructure close to its limits. In a statement titled To Kimi Users: An Update on Compute Capacity Constraints and Subscription Suspension, the company said user requests in the 48 hours […]
Honor confirms August global launch of its first Robot Phone at WAIC 2026Mon, 20 Jul 2026 02:27:12 +0000 At the 2026 World Artificial Intelligence Conference (WAIC), Honor CEO Li Jian unveiled the company’s first Robot Phone, confirming it will launch globally in August with pre-orders now open across all sales channels. The device is powered by Qualcomm’s latest Snapdragon 8 Elite Gen 5 platform and features a 1.5K flat display with ultra-narrow, symmetrical […]
XPeng launches MONA L03 in Munich, taking aim at Europe’s electric SUV marketFri, 17 Jul 2026 03:15:34 +0000 On Thursday, XPeng unveiled the MONA L03 smart SUV at its global launch event in Munich, Germany. The model will be launched in 65 countries and regions, including China, Europe, and other overseas markets, according to the Chinese automaker. The launch marks a strategic move in XPeng’s global expansion, as the MONA L03 is the […]
Apple CEO Tim Cook and successor John Ternus meet POP MART founder Wang Ning at Apple ParkThu, 16 Jul 2026 07:42:27 +0000 Apple CEO Tim Cook posted on Weibo today, welcoming the POP MART team to visit Apple Park, Apple’s headquarters in Cupertino, California. He also shared a photo of himself with Apple’s incoming CEO John Ternus and POP MART founder Wang Ning during their meeting. This marks the second public interaction between Cook and POP MART […]
Xiaomi introduces Xiaomi-Robotics-U0 for embodied AI and robot generationThu, 16 Jul 2026 03:25:30 +0000 Xiaomi on Wednesday unveiled Xiaomi-Robotics-U0, a 38-billion-parameter multimodal autoregressive foundation model for embodied AI. The company said the model unifies four core capabilities within a single framework: embodied scene generation, embodied transfer, robot interaction video generation, and general-purpose image generation and editing. According to Xiaomi, the model can generate robot-ready environments from text prompts, adapt […]
Baidu to power AI search for Apple’s Apple Intelligence in ChinaThu, 16 Jul 2026 02:54:58 +0000 According to sources, Apple and Baidu are partnering to bring AI features to iPhone users in China. Baidu is developing an AI-powered search experience as part of the Apple Intelligence suite, enabling image and text understanding while also enhancing Siri with capabilities tailored for the Chinese market. Combined with Alibaba’s Qwen large language model, which […]
Alibaba’s Qwen to be integrated into Apple IntelligenceWed, 15 Jul 2026 08:45:37 +0000 Alibaba’s Qwen AI model will be integrated into Apple Intelligence, bringing AI-powered experiences to users in China across iOS, iPadOS, macOS, and visionOS. Without switching between apps, users will be able to access Qwen’s capabilities—including text and image understanding, as well as content generation—directly on Apple devices. Today, China’s Cyberspace Administration announced the filing of […]
TSMC to raise mature-node foundry prices starting January 2027Wed, 15 Jul 2026 05:55:25 +0000 According to multiple Taiwanese media reports, several chip design companies have recently received price hike notices from TSMC, with foundry prices for mature process nodes set to increase from January next year. The exact adjustment will vary by customer. Analysts say rising AI demand, product mix optimization, and higher upstream material costs have extended pricing […]
DeepSeek founder Liang Wenfeng’s fortune rises to $36 billionWed, 15 Jul 2026 04:29:11 +0000 DeepSeek founder Liang Wenfeng now has an estimated net worth of $36 billion, more than double his previous estimate of $16.7 billion, according to the Bloomberg Billionaires Index. The increase makes Liang the wealthiest founder among companies whose primary business is AI models, according to Bloomberg’s comparison. He now ranks above Anthropic co-founder Dario Amodei […]
CXMT sets IPO price at RMB8.66 per shareWed, 15 Jul 2026 04:27:23 +0000 CXMT, a Chinese DRAM chipmaker, has set the price of its Shanghai STAR Market IPO at RMB8.66 per share. The company will offer 6.69 billion shares, with online and offline subscriptions scheduled for July 16. The offering is expected to raise about RMB57.9 billion ($8.55 billion) before any over-allotment option, giving CXMT an implied post-IPO […]
DeepSeek may file mainland IPO application this yearWed, 15 Jul 2026 03:43:37 +0000 DeepSeek, the Hangzhou-based AI model developer, has begun preparing for a mainland IPO and may file its listing application as soon as this year, according to Bloomberg, citing people familiar with the matter. The company is targeting a 2027 debut. DeepSeek is in talks with accounting and banking advisers and is seeking additional private funding […]
SHEIN receives CSRC filing notice for Hong Kong listingWed, 15 Jul 2026 03:42:33 +0000 SHEIN Global Holdings Limited, the company behind China-founded fashion e-commerce platform SHEIN, has received a filing notice from China’s securities regulator for a proposed listing on the Hong Kong Stock Exchange. The notice, issued on July 10, was based on materials submitted through the company’s mainland operating entity, Guangzhou Shein International Import & Export Co., […]
Xiaomi updates progress on humanoid robots in auto factory, achieves 98% success rate in some tasksWed, 15 Jul 2026 02:14:13 +0000 Xiaomi has revealed the latest progress of its humanoid robot deployed in an automotive factory. Following four months of iteration, the robot’s success rate at a self-tapping nut loading station has risen from 90.2% to 98%, narrowing the gap with human workers’ qualification rate to just one percentage point, according to the company. The company […]
QuestMobile: China’s AI-native apps reach 499 million monthly active usersTue, 14 Jul 2026 06:17:37 +0000 China’s AI-native apps recorded 499 million monthly active users by May 2026, up 85.4% from a year earlier, according to QuestMobile’s 2026 first-half report released on July 14. Doubao, Qwen and DeepSeek formed the top tier, with 382 million, 167 million and 130 million monthly active users, respectively. The report measured AI-native apps separately from […]
SenseTime open-sources SenseNova-Vision unified vision modelTue, 14 Jul 2026 06:15:52 +0000 SenseTime has released and fully open-sourced SenseNova-Vision, a unified vision model in its SenseNova foundation-model suite. The model is designed to handle object detection, optical character recognition, keypoint localization, image segmentation, depth estimation and 3D reconstruction within one system, instead of relying on separate specialist models for each task. The model also supports dense geometric […]
China’s electric vehicle exports rise 68.7% in H1 2026Tue, 14 Jul 2026 06:13:29 +0000 China’s electric vehicle exports rose 68.7% year-on-year in the first half of 2026, according to customs data released on July 14. Exports of electric motorcycles and bicycles increased 31.5%, electric locomotives 45.1%, lithium batteries 37.6% and wind turbines 35.6%. The same data showed that exports of AI-integrated intelligent bionic robots exceeded 10,000 units and reached […]
Marvel-Tech raises more than RMB500 million across two financing roundsTue, 14 Jul 2026 06:08:34 +0000 Shanghai-based Marvel-Tech, a developer of gas turbines and industrial waste-heat and waste-pressure recovery turbine systems, has completed two consecutive financing rounds totaling more than RMB500 million. The C round was led by HongShan, while the B round was jointly led by C&D Emerging Investment and Qiming Venture Partners. The company said the funds will support […]
Amap launches ABot-World Studio for interactive video and 3D scene generationTue, 14 Jul 2026 06:05:21 +0000 Amap, Alibaba’s digital mapping and navigation platform, has launched ABot-World Studio and opened it for testing. The product combines interactive video generation with 3D Gaussian splatting, allowing users to create explorable 3D scenes from text or images rather than producing only a fixed video. ABot-World Studio is part of Amap’s broader ABot world-model product line. […]
ByteDance denies plans to enter smart driving businessTue, 14 Jul 2026 05:55:57 +0000 ByteDance has denied reports that it plans to enter the autonomous driving sector. Recent media reports claimed the company was exploring autonomous driving, with a particular focus on driverless logistics, and that the initiative would fall under the automotive division of ByteDance’s cloud platform, Volcano Engine. Responding to China Star Market, ByteDance said: “ByteDance is […]
miHoYo launches AI companion app BSide: Olivia Lin on Steam Early AccessTue, 14 Jul 2026 02:36:39 +0000 On Monday, Chinese gaming firm miHoYo launched Early Access for its AI companion app, BSide: Olivia Lin, on Steam. Unlike the studio’s anime-style games, the new release is listed as a Free to Play Utility rather than a game, marking miHoYo’s latest effort to expand beyond interactive entertainment and into AI-powered digital companionship. At the […]
Chinese internet firms sign AI agent data protection pactMon, 13 Jul 2026 09:38:53 +0000 The China Internet Association released a self-regulatory pact on personal information protection for AI agents at a forum in Beijing, with Baidu, Tencent, Alibaba, Volcengine, and 27 other internet companies among the first signatories. The pact is aimed at standardizing how AI agents collect, process, and use personal data as agent-based services spread across internet […]
China sets 2030 target for next-generation internet infrastructureMon, 13 Jul 2026 09:33:37 +0000 China’s Ministry of Industry and Information Technology and three other agencies issued guidelines on July 13 to upgrade the country’s internet basic resources, targeting “systematic breakthroughs” by 2030 and a more advanced national internet infrastructure by 2035. The document calls for research into agent-to-agent networks, satellite internet, digital identity infrastructure, IPv6 upgrades, and the integration […]
Ant Group unveils AI safety models for agents and multimodal systemsMon, 13 Jul 2026 09:31:31 +0000 Ant Group’s AI Safety Lab has open-sourced SingGuard-NSFA, a safety guardrail model for autonomous agents, and disclosed details of SingGuard, a multimodal safety model. SingGuard-NSFA is designed to detect risks such as prompt injection, sensitive data theft, malicious code execution, resource abuse, and permission misuse before agents take action. The model covers seven major risk […]
Zhipu AI founder outlines Touch High plan for AGI researchMon, 13 Jul 2026 09:30:37 +0000 Zhipu AI founder Tang Jie told employees in an internal letter that the Chinese foundation model developer will launch a “Touch High” plan, focusing on AGI research rather than short-term commercialization, according to LatePost. Zhipu AI is the company behind the GLM series of large language models. Tang listed four technical priorities for the plan: […]
ByteDance explores autonomous driving for unmanned logisticsMon, 13 Jul 2026 09:29:15 +0000 ByteDance is exploring autonomous driving technology for unmanned logistics through the world model team under Seed, its AI research unit, according to Chinese media reports. The early-stage project is reportedly tied to Volcengine’s automotive industry line. ByteDance said its large model research includes early exploration in physical AI, but added that it has no plan […]







 ClickLock Stealer
ClickLock Stealer


 Journaling with mindfulness
Journaling with mindfulness





 Apple once again crowned Most Valuable Company
Apple once again crowned Most Valuable Company Apple One
Apple One Apple Music raises prices
Apple Music raises prices
 iPhone 17
iPhone 17